Imagine this: You're a major financial services company that just launched an innovative initiative to share customer insights with research partners. After months of careful preparation, you've generated synthetic data from millions of customer service interactions, confident in your privacy-preserving techniques. The dataset goes live on Monday. By Wednesday morning, your worst nightmare unfolds - security researchers have found actual customer names, email addresses, and sensitive financial details embedded in your synthetic data. Your privacy guarantees, it turns out, weren't as watertight as you thought.
This isn't a hypothetical scenario. As our research shows, even sophisticated privacy-preserving techniques can fail in subtle and dangerous ways.
Critical Findings
Our recent audit of a financial synthetic dataset containing 1034 samples revealed interesting results. Despite implementing differential privacy with an epsilon(privacy leakage budget) value of less than 10 (ε=8) - a setting typically considered conservative - we discovered:
- 100+ potential names
- 50+ organization identifiers
- 20+ phone numbers
- Multiple email addresses and locations
These findings highlight concerning privacy vulnerabilities in this financial dataset. Most
alarmingly, we were able to verify multiple instances of matching triplets (name, phone number, and
email address) belonging to the same real-world individuals.
Note: This analysis was completed overnight by two graduate students using only local
machines, without access to closed-source LLM APIs.
A motivated threat actor could likely
extract substantially more sensitive information with additional resources.
Case Study: GretelAI's Synthetic Financial Dataset
GretelAI recently released a synthetic financial risk analysis dataset (gretel-financial-risk-analysis-v1) on HuggingFace, implementing differential privacy with ε=8. The dataset was generated using their proprietary platform, reportedly fine-tuned on 14,306 SEC filings from 2023-2024. They assert their implementation includes automated quality and privacy testing, along with structure-preserving text generation capabilities.
While differential privacy provides valuable theoretical guarantees, real-world applications benefit from additional evaluation perspectives. Enhanced documentation of testing methodologies and privacy evaluation metrics could provide valuable insights for practitioners implementing similar systems. The intersection of theoretical privacy guarantees and practical privacy preservation presents opportunities for developing more comprehensive evaluation frameworks.
Our investigation explores two key aspects: first, evaluating the diversity and representativeness of the synthetic data through cluster analysis, and second, conducting a comprehensive privacy audit to identify potential information leakage. This analysis aims to contribute to the broader discussion of privacy evaluation methodologies in synthetic data generation, particularly focusing on the complementary role of empirical testing alongside theoretical guarantees.
Key Privacy Challenges
1. The Missing Privacy Unit Definition
Most implementations fail to specify exactly what they're protecting. Is it individual customers? Organizations? Documents? Without this crucial definition, users can't properly evaluate or trust privacy guarantees. A unit of privacy should be defined and ideally reported.
2. The DP-SGD Fallacy
Differential Privacy Stochastic Gradient Descent (DP-SGD) alone isn't enough. Our analysis shows that focusing on only mathematical privacy while ignoring practical privacy measures can leave significant vulnerabilities.
3. Scale Changes Everything
Privacy guarantees that work in research papers often break down at scale. Research experiments typically use specific models and limited datasets with known distributions, where epsilon recommendations are inherently both model and data-dependent.
4. The Epsilon Illusion
Low epsilon values (ε<10) don't automatically guarantee privacy. Context matters more than numbers - what's safe for one application might be dangerous for another.
5. The Audit Gap
Comprehensive pre-release privacy auditing is essential for synthetic data. This should include manual inspection of dataset subsamples and systematic attack simulations (e.g., membership inference, re-identification, canary insertion).
6. Security Through Obscurity Doesn't Work
Just as in encryption, hiding your privacy mechanisms doesn't make them more secure. Transparency enables community verification and improvement.
Recommendations
For Organizations
- Explicitly define and document your privacy unit
- Implement multi-layered privacy protections beyond DP
- Conduct comprehensive pre-release privacy audits
- Develop context-specific privacy parameters
- Be transparent about your privacy mechanisms
For Practitioners
- Don't trust epsilon values without context
- Verify privacy guarantees empirically
- Consider multiple attack vectors in testing
- Document all privacy decisions and trade-offs
Our Analysis Methods
We approached the privacy analysis of this synthetic dataset through two methods:
- Method 1: Auxiliary Information Attacks - A practical approach demonstrating how real-world attackers could exploit the synthetic data to reveal private informatio using external data
- Method 2: Structural Analysis - A systematic examination of the dataset's patterns and characteristics to understand how privacy vulnerabilities emerge
Method 1: Auxiliary Information Attack - Linking the Unlinked
Linkage attacks represent a significant vulnerability in privacy-preserving data publishing, where an attacker can combine the released data with publicly available information (auxiliary information) to re-identify individuals or entities in the dataset. This auxiliary information could be anything from public records and social media profiles to company websites and SEC filings. The power of these attacks lies in their ability to bridge gaps in anonymized data by leveraging contextual information that wasn't considered during the anonymization process.
In the context of synthetic data generation, even when specific identifiers are masked or replaced with generic terms, the surrounding context and specific phrases can create unique fingerprints that, when combined with public information, can lead to successful re-identification. This becomes particularly concerning when dealing with financial documents where specific legal phrases, dates, and transaction details can create unique, searchable combinations.
In our analysis of this synthetic dataset, we discovered multiple instances where such linkage attacks were possible. Here's a demonstrative example:
...On October 21, 2022, the Company entered into an amendment to the Credit Agreement, dated as of July 15, 2020 (the ""Original Credit Agreement""), among the Company, the lenders named therein, and JPMorgan Chase Bank, N.A., as administrative agent for the lenders (the ""Amended Credit Agreement""). The Amended Credit Agreement amends and restates the Original Credit Agreement in its entirety. The Amended Credit Agreement provides for a new credit facility of $1.25 billion, which includes a $1.0 billion revolving credit facility and a $250 million term...
...is available for review on www.aptiv.com under the Investors section. The Company's entry into the Amended Credit Agreement is expected to provide the Company with increased financial flexibility and liquidity to support its business operations and strategic...
The search query that reveals the original document:
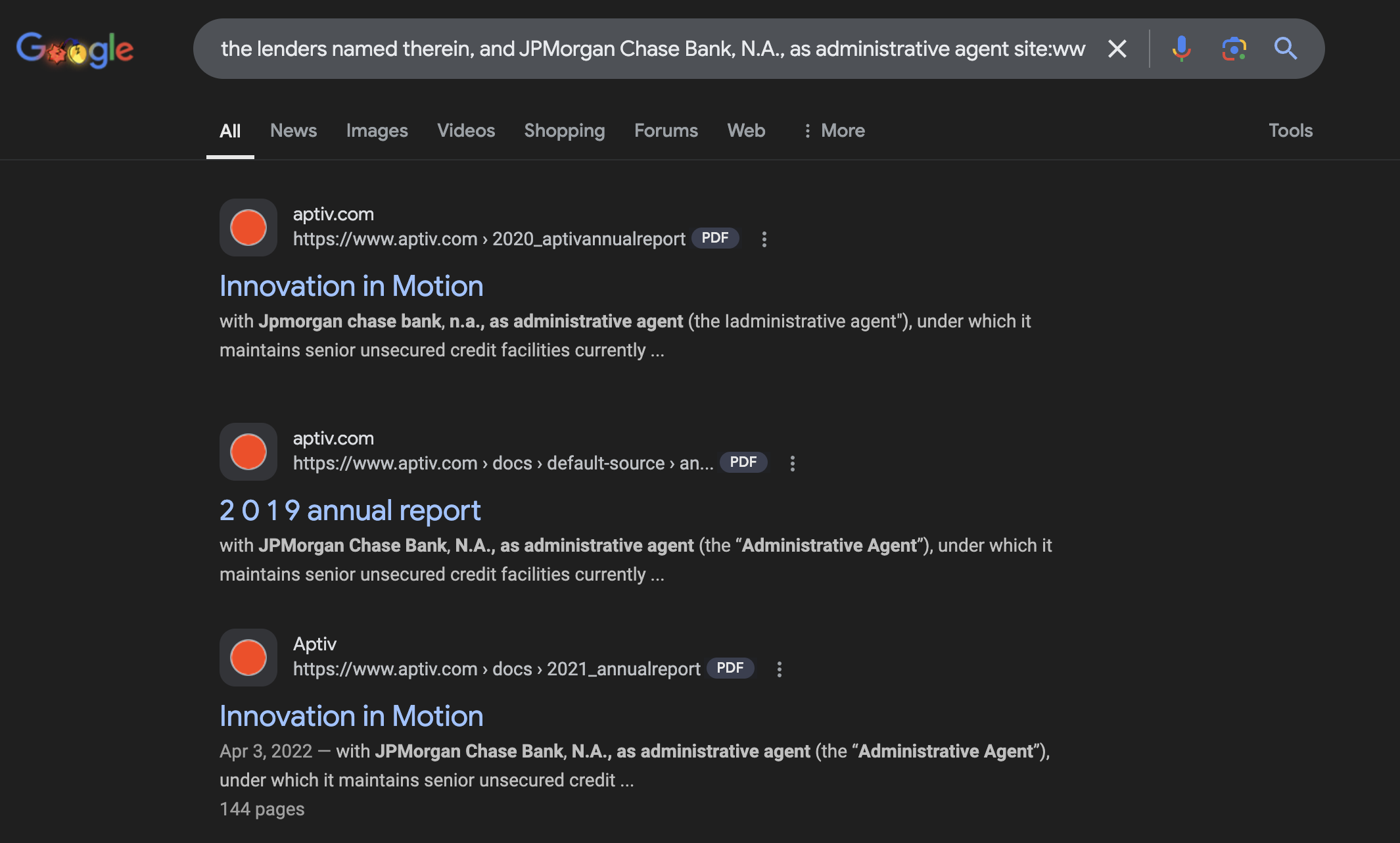
This example demonstrates how even carefully anonymized synthetic data can leak identifying information. Despite replacing the company name with the generic phrase "the Company", the presence of specific legal phrases combined with the website URL creates a direct link to the original entity. The match of multiple data points across different parts of the text provides high-confidence identification, undermining the privacy guarantees of the synthetic data generation process.
Method 2: Structural Analysis
1. PII Identification and Masking
What we did? We used three types of NER models
to identify PII and Mask in the dataset: spaCy(en_core_web_lg-3.8.0),
Gliner(gliner-bi-small-v1.0),
and Gretel Gliner(gretel-gliner-bi-small-v1.0).
We identified PIIs like names, emails, organizations, locations, and phone numbers. We then
anonymized the PIIs by replacing them with placeholders like <NAME>, <EMAIL>,
<ORGANIZATION>, <LOCATION>, and <PHONE>.
Results: Spacy identified significantly more
PII instances (>100x) compared to Gretel's GLiNER PII detection model. While Spacy did have
some false positives, Gretel's model demonstrated notably higher false negatives - a
critical concern for privacy preservation.
2. Clustering Analysis: K-Means
Results: The kneedle algorithm consistently identified 8 as the optimal number of clusters across different PII masking approaches. This was particularly interesting as the original dataset reportedly contained only 3 kinds of documents, i.e., 10-K, 10-Q, and 8-k SEC filings drawn from a set of 14,306 documents. Inertia began to plateau around number of clusters equaling 8.
3. Distribution Analysis
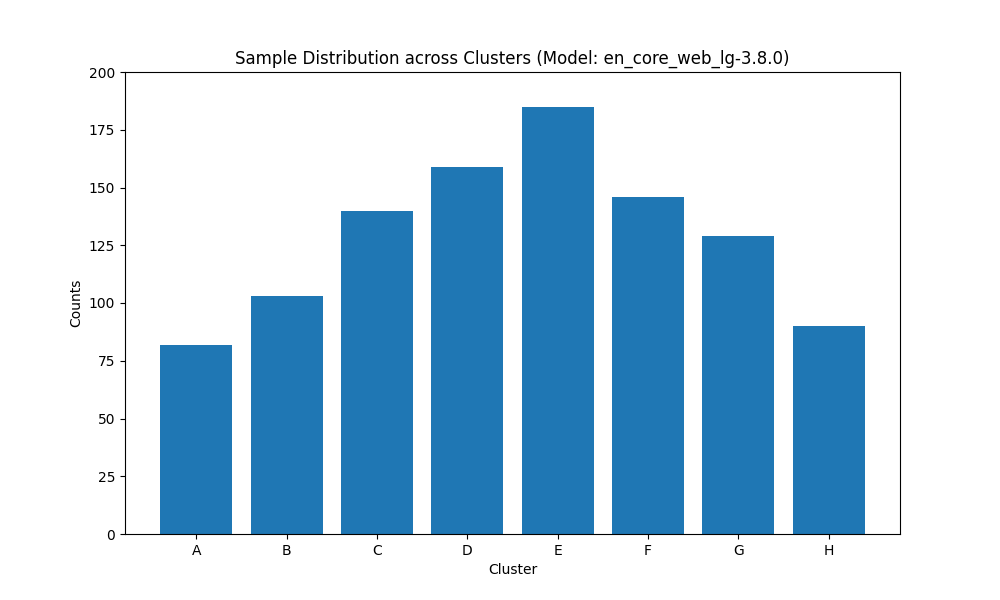
What we did? We analyzed the distribution of
documents across the identified clusters by computing document frequencies per cluster. We
performed this analysis separately on the outputs from each PII detection model. We present
the results of frequency count across cluster heads for spaCy here.
Results: The distribution of documents across
clusters shows an intriguing near-normal pattern. This could either emerge from template
distributions in the original dataset or be a result of the DP-SGD training process,
assuming they considered each document as a sample set or unit of privacy. Determining the
exact cause would require access to Gretel's training dataset, which wasn't publicly
disclosed (at least which organization's SEC filings were used for training).
4. Privacy Leakage Analysis
What we did? We investigated potential
relationships between cluster sizes and PII leakage by visualizing PII count distribution
across cluster sizes (X-axis is re-scaled). For each cluster, we aggregated the number of
PIIs detected by each model and analyzed their relationship with cluster size.
Results: We found no trend between cluster size
and PII frequency. This could suggest that PII leakage occurs uniformly across clusters,
regardless of their size, indicating a systematic rather than cluster-specific privacy
vulnerability.

Reflecting On This Work
Is "publicly accessible" personal data not subject to privacy considerations?
The argument that information available in SEC filings is already public and thus exempt from privacy protections overlooks crucial aspects highlighted by Tramer, Kamath and Carlini in their ICML best paper. They emphasize that "The Web contains privacy-sensitive data. Training data scraped from the Web is indeed publicly accessible, but this does not imply that using this data in machine learning applications poses no privacy risks." Individuals often share information online for specific contextual purposes - for instance, contact information in SEC filings is intended for official business communications. The authors note that "people often underestimate how much information about them is accessible on the Web, and might not consent to their 'publicly accessible' personal data being used for training machine learning models." This paper has an example detailing this scenario in Section 2.1.
Does widespread availability constitute consent for unrestricted use?
The paper argues that public accessibility doesn't imply blanket consent for all downstream uses. When data subjects notice their information being leaked by models trained on public data, explanations that "this data was public" may not align with privacy expectations or norms. This creates what the authors describe as potential "erosion of trust" in privacy-preserving technologies. The situation is particularly relevant for SEC filings where standardized formats and legal language can create unique, identifiable patterns - information published for regulatory compliance may be repurposed in ways never intended by the data subjects. This raises critical questions about appropriate use of public data in model training and the need for more nuanced frameworks that respect contextual integrity while preserving utility.
Is Differential Privacy properly implemented and sufficient for SEC filings?
The dataset claims to be "synthetic financial risk analysis text generated using differential privacy guarantees, trained on 14,306 SEC (10-K, 10-Q, and 8-K) filings from 2023-2024." However, this raises critical questions about privacy units and guarantees. Organizations contribute multiple filings (10-K, 10-Q, and 8-K) over time, suggesting the privacy unit should be at the organization level rather than the document level. Moreover, there's no specification of the δ parameter, which represents the probability of catastrophic privacy failure - a crucial consideration when dealing with organizational data that appears multiple times in the dataset. The implementation is inspired by Yue et al. (2023), who demonstrated that even with strong privacy parameters, "some canaries (e.g., Address and Plate in Figure 5) still obtain top ranks. This indicates that even if certain private information appears only once in the training set, models may still memorize it, potentially leading to leakage in synthetic generations."
Is PII detection and stripping sufficient for protecting privacy in synthetic text generation?
As Xin et al. (2024) emphasize, "Our main finding is that current dataset release practices for text data often provide a false sense of privacy." The challenges extend beyond simple PII removal and require a comprehensive approach with multiple layers of protection. This includes robust privacy checks both before and after generation (using ensemble PII detection through multiple models to capture different types of identifiable information), specifically addressing the unique challenges of structured documents. The protection mechanisms need to account for both the structured nature of SEC filings and the potential for information leakage through writing style, document structure, and technical content - not just preserving these elements for utility but specifically protecting against their potential use as privacy attack vectors.
Looking Ahead
This analysis has highlighted some interesting challenges in the practical implementation of privacy-preserving synthetic data. While differential privacy provides strong theoretical foundations, our findings suggest that bridging the gap between theory and practice remains complex. The patterns we observed in this dataset raise questions about how we evaluate privacy in synthetic data beyond mathematical guarantees.
We were particularly intrigued by how traditional measures of privacy didn't capture some of the information leakage patterns we found through basic empirical testing. This suggests there might be value in combining theoretical privacy guarantees with straightforward practical checks during the development process.
We look forward to exploring these questions further and seeing how the field of privacy-preserving synthetic data continues to evolve.